Having content entered multiple times across different online professional platforms seems to invite inconsistency.
One might, for example, feel compelled to enter publications into LinkedIn when they are already captured automatically elsewhere (more comprehensively), such as Google Scholar, and make either intentional or accidental alterations in doing so.
At the same time, not doing this may result in a fragmented profile.
In an attempt to solve this problem, the most recent iteration of martinchapman.co.uk (~2018) was designed to automatically aggregate content from multiple platforms, providing a single, comprehensive, dynamically generated biographic source (pictured).
This also eliminates the need for manual updates, and ensures that all biographical content is centred around outputs.
The process of creating this site is documented below.
First pass
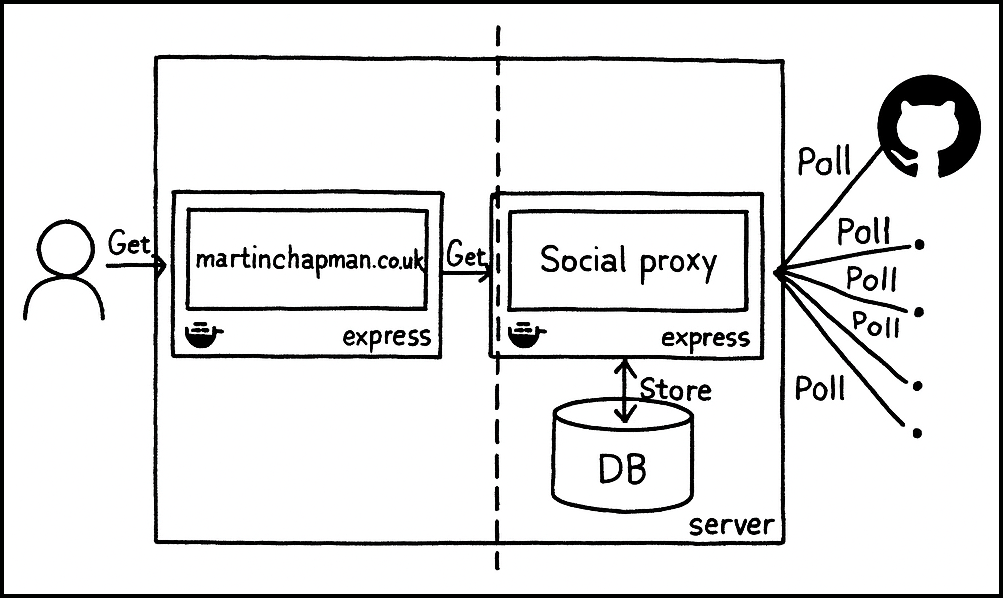
The first pass of creating such a site resulted in what could be loosely described as a microservice architecture, containing two services: a ‘social proxy’ service and the site service itself (‘martinchapman.co.uk’) (pictured).
These services were realised as dockerised Express (Node.js) servers, running on a single self-hosted server.
A range of content platforms—including GitHub, as in this example—were polled periodically by the social proxy (typically manually initiated), using their standard APIs.
Content, such as a list of repos, was then stored locally (cached) in a database.
If APIs weren’t available (e.g. LinkedIn), content was mocked in the database.
Thus, everything to the right of the dashed line happened asynchronously, in an effort to improve response time and limit API endpoint load.
When it came to a user making a request (left of the dashed line), the site service would, in turn, call the social proxy to access aggregated platform content (from its database), combine it, use it as the basis for rendering a pug template, and display it back to the user.
Second pass
Motivated by a general move away from Express in other development work (to either FastAPI or Fastify), and a desire to no longer self-host the site, a new architecture was developed in 2023.
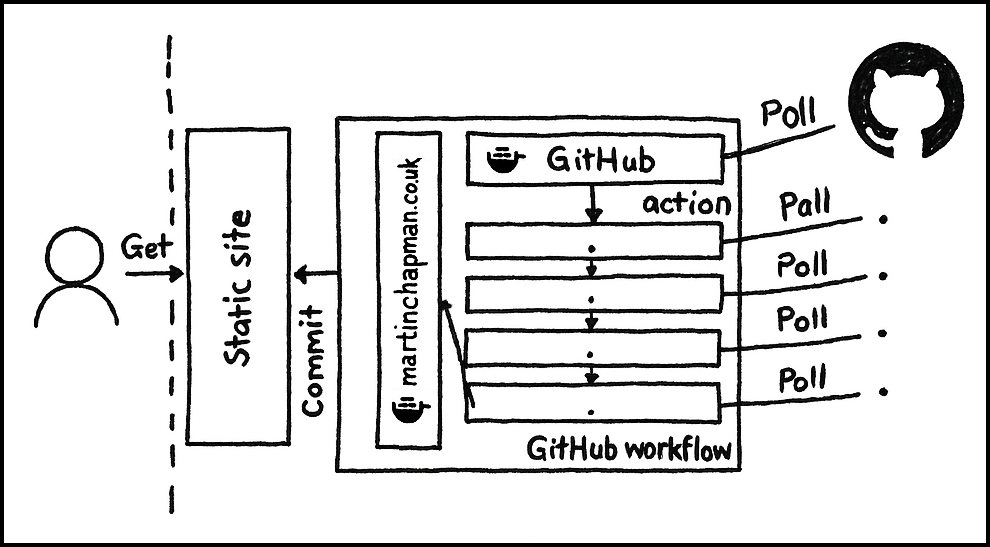
Here, each piece of polling functionality for each platform is retained, except split into separate dockerised services, rather than a single service (pictured).
These services form the basis for individual GitHub actions, which are called within a GitHub workflow.
These actions are linked together to, for example, combine platform output, e.g. linking to a YouTube-based presentation of a slide deck originally sourced from Slideshare.
As before, if APIs are not available, the content is hardcoded into each service.
At the end of these actions, the final aggregated content is passed to the site generator, now also part of a GitHub action, which again outputs content to display to the user.
This time, however, the output is committed to a GitHub repository to be served to a user as a static site from GitHub pages.
Thus, much more of the process happens asynchronously, on GitHub.
Although the static site generation process is simpler, one does lose some flexibility, such as custom paths that—via a full web server—perform arbitrary lookups against the aggregated platform data, such as one for publications that contain certain words (https://martinchapman.co.uk/publications/pheno/).
This can be replicated by adding another output step to the GitHub workflow, but it is not truly dynamic.
Current services
Both iterations of this platform provided the desired aggregation of online professional platform content (pictured). An overview of what is aggregated and from where is shown below.
| content | platform | combines with |
|---|---|---|
| Software developed and languages used | GitHub | - |
| Tools used | StackShare (via GitHub) | - |
| Papers published | Google Scholar (mocked) | - |
| Talks/lectures given | Slideshare | - |
| Talks/tutorials given | YouTube | Slideshare |
| Funding obtained | Orcid | - |
| Academic service | Orcid (planned) | - |
| Student projects | GitHub and Slideshare | - |
| Projects | LinkedIn (mocked) | GitHub, Google Scholar, Slideshare and Orcid |
| (For fun) Films watched | Trakt | - |
| (For fun) Total Lego sets collected | Brickset (via Rebrickable) | - |
Critique
As with most automation endeavours, there is a risk that the effort taken to make something happen automatically outweighs the effort that would be spent completing the same task manually. As of now, this may be true of this approach, but over time—with, among other things, a reduction in duplication errors—it is likely that the effort spent will start to pay off. Automated (and potentially over-engineered) solutions are also often more entertaining.
As what is aggregated from these various platforms is text-based, there is the argument that the content of the site is too text-heavy.
Finally, lots of technical overcomplication also remains, given the transition from Express to GitHub pages, with each service still effectively outputting content based on mechanisms designed to serve web-based requests directly.